起因还要从我正在做的第二个项目说起。
我一直想要有一款软件:可以记录自己的待办,记录自己的零碎想法,能够很方便的做计划,然后还可以定期复盘。我找了很久,试过滴答清单、flomo、wolai、flowus、obsidian,还有各种习惯打卡的 app。但是每个软件都没有使用很久,总会有一些不符合我习惯的别扭感。最后我决定自己写一个。
但我是个前端,涉及后端的东西我并不擅长。好在有AI帮忙出技术方案,最终选定用 Supabase 做后端数据库(免费额度够用,还自带用户认证),前端用 Cloudflare Pages 部署(免费额度比 Vercel 大方太多),ORM 用 Drizzle,查询写起来更符合 TypeScript 的风格。
本地开发一切顺利,两个月后 MVP 版本出炉。我兴冲冲地部署上线,然后 —— 连不上服务器。
这一卡,就是半个月。
核心问题
1. Cloudflare Pages 的 serverless function
Cloudflare Pages 的 serverless function 是基于 Cloudflare Worker 的。Worker 运行在 Cloudflare 的边缘节点上,和传统的 Node.js 环境有很大不同。Worker 默认情况下是没有 Node.js 的内置模块,默认不保持长连接,每次请求独立。
Drizzle 通过 pg 模块使用 TCP 协议连接数据库,而 pg 依赖的长连接池机制与 Cloudflare Worker 的运行时环境不兼容 —— Worker 的每个请求都是独立短生命周期的,无法维持持久的 TCP 连接。
后来折腾出一种方式可以短暂的链接成功:那就是每个请求建立一个单独的链接,然后在请求结束后关闭链接。这样就不会有长连接的问题了。但是这样做的性能非常差,每次请求都要建立和关闭连接,开销很大。随便访问几次页面就会碰到 cloudflare 的 cpu 限制,导致请求被中断。
2. 什么是 Hyperdrive
Cloudflare Hyperdrive 是一项专为 Cloudflare Workers 设计的服务,旨在大幅加速其访问传统数据库(如 PostgreSQL 和 MySQL)的速度。它通过在全球边缘网络建立连接池和智能缓存,大幅度提升数据库的访问效率。
- 显著降低延迟:消除冗余网络往返,可为每次查询节省数百毫秒
- 减少数据库负载:通过连接复用和查询缓存,有效降低源数据库的 CPU 和连接数压力
- 无需修改代码:它兼容现有的数据库驱动和库,你只需更换连接字符串,无需重写查询
看来事件出现了转机。于是我开始折腾基于 Hyperdrive 的链接方式。这需要我即保留本地开发环境原本的链接方式,在线上环境又要使用 Hyperdrive 的链接方式。
最终答案
Cloudflare 的配置
配置有几种方式可以选择。可以把相关的变量配置写到代码中,比如用 wrangler.toml 配置文件。如果本地有这个文件,部署到线上后,cloudflare pages 会自动读取这个文件中的配置。好处就是要修改什么配置不用去管理后台了,直接代码里操作。反正每次修改配置,都要重新部署一遍的。缺点也很明显:如果都放这里的话,数据库的密码就暴漏在代码里了。另外一种就是在 cloudflare pages 的后台配置环境变量,这样不会暴露数据库密码。
首先,要创建一个 Hyperdrive binding。这个 binding 是一个 cloudflare pages 的资源,绑定了一个数据库的连接。具体创建方式我就不赘述了,网上很多资料。创建好后,要去自己的 page 项目中,打开 settings。
- 在 Bindings 的栏目里进行绑定刚才创建的 Hyperdrive。注意,绑定时,设定的 name 名称要跟代码里的名称一致。
- 在 Compatibility Flags 里,添加
nodejs_compat和no_nodejs_compat_v2 - 此时
Variables and secrets原来的环境变量会清空,需要重新添加secrets。主要是:SUPABASE_KEY和SUPABASE_URL。- 因为前面开启了那两个 flag 后,要求所有的环境变量都要是 secret 才能使用。secrets 也是环境变量,只是值不再能查看,只会在服务端运行时可以获取到,安全性更高而已。
PS:Cloudflare pages 默认是支持 production 和 preview 两个环境的,想要两边都使用,需要分别配置。
代码
client.ts drizzle 连接数据库的入口文件
import { drizzle, type PostgresJsDatabase } from "drizzle-orm/postgres-js";
import postgres from "postgres";
import { tables } from "./schema";
type BaseCloudflareHyperdriveBinding = {
connectionString: string;
};
type BaseCloudflareRuntimeEnv = Record<string, unknown>;
type BaseHyperdriveGlobalScope = typeof globalThis & {
__DAYFLOWY_HYPERDRIVE_CONNECTION_STRING__?: string;
};
export type DrizzleDb = PostgresJsDatabase<typeof tables>;
// 全局变量的引用
const hyperdriveGlobalScope = globalThis as BaseHyperdriveGlobalScope;
const resolveCloudflareBindingConnectionString = (): string | undefined => {
// 从全局变量上取 hyperdrive 的连接字符串
const connectionString =
hyperdriveGlobalScope.__DAYFLOWY_HYPERDRIVE_CONNECTION_STRING__;
return typeof connectionString === "string" &&
connectionString.trim().length > 0
? connectionString.trim()
: undefined;
};
// 获取最终的数据库链接地址
const resolveDatabaseUrl = (): string | undefined => {
return (resolveCloudflareBindingConnectionString() ||
process.env.DATABASE_URL ||
process.env.SUPABASE_DB_URL) as string | undefined;
};
// drizzle 链接数据库的函数,业务方可以通过返回的实例来操作数据库
export function useDb(): DrizzleDb {
const databaseUrl = resolveDatabaseUrl();
if (!databaseUrl) {
throw new Error(
"Missing database connection. Configure Hyperdrive binding or DATABASE_URL/SUPABASE_DB_URL.",
);
}
if (
!databaseUrl.startsWith("postgres://") &&
!databaseUrl.startsWith("postgresql://")
) {
throw new Error(
"Invalid DATABASE_URL/SUPABASE_DB_URL for Drizzle client. Expected postgres://... or postgresql://...",
);
}
const sql = postgres(databaseUrl, {
prepare: false,
});
return drizzle(sql, {
schema: tables,
casing: "snake_case",
});
}
// 最关键的是这里,从环境变量中获取 hyperdrive 的连接字符串
export const cacheHyperdriveConnectionString = (
env: BaseCloudflareRuntimeEnv | undefined,
): void => {
// env 的入参是在线上环境中 cloudflare pages 的 serverless function 的环境变量对象,里面包含了 hyperdrive 的 binding
if (!env) {
return;
}
// 这里的 HYPERDRIVE_BINDING_NAME 是在 cloudflare pages 的环境变量中配置的,指向 hyperdrive 的 binding 名称
const bindingName = (
process.env.HYPERDRIVE_BINDING_NAME || "HYPERDRIVE"
).trim();
// 根据配置的名称,从线上环境变量里获取 hyperdrive 的 binding 对象
const binding = env[bindingName] as
| BaseCloudflareHyperdriveBinding
| undefined;
// 从 binding 对象中获取连接字符串 - hyperdrive 连接数据库的连接
const connectionString = binding?.connectionString;
if (
typeof connectionString !== "string" ||
connectionString.trim().length === 0
) {
return;
}
// 将连接字符串缓存到全局变量中,供后续使用
hyperdriveGlobalScope.__DAYFLOWY_HYPERDRIVE_CONNECTION_STRING__ =
connectionString.trim();
};
server/middlewares/hyperdirve-context.ts
// 在服务端增加一个中间件,每次请求时,都获取线上的环境变量,并缓存 hyperdrive 的连接字符串到全局变量中,供 drizzle 链接数据库时使用
import { cacheHyperdriveConnectionString } from "PATH_TO_CLIENT/client.ts";
export default defineEventHandler((event) => {
const contextEnv = (
event.context.cloudflare as { env?: Record<string, unknown> } | undefined
)?.env;
const runtimeEnv = (
event.req as {
runtime?: { cloudflare?: { env?: Record<string, unknown> } };
}
).runtime?.cloudflare?.env;
cacheHyperdriveConnectionString(contextEnv ?? runtimeEnv);
});
配置弄好,代码改好后,就可以部署到线上了。访问页面,终于可以正常访问数据库了。Hyperdrive 的 metrics 中也终于可以正常显示数据流量了:
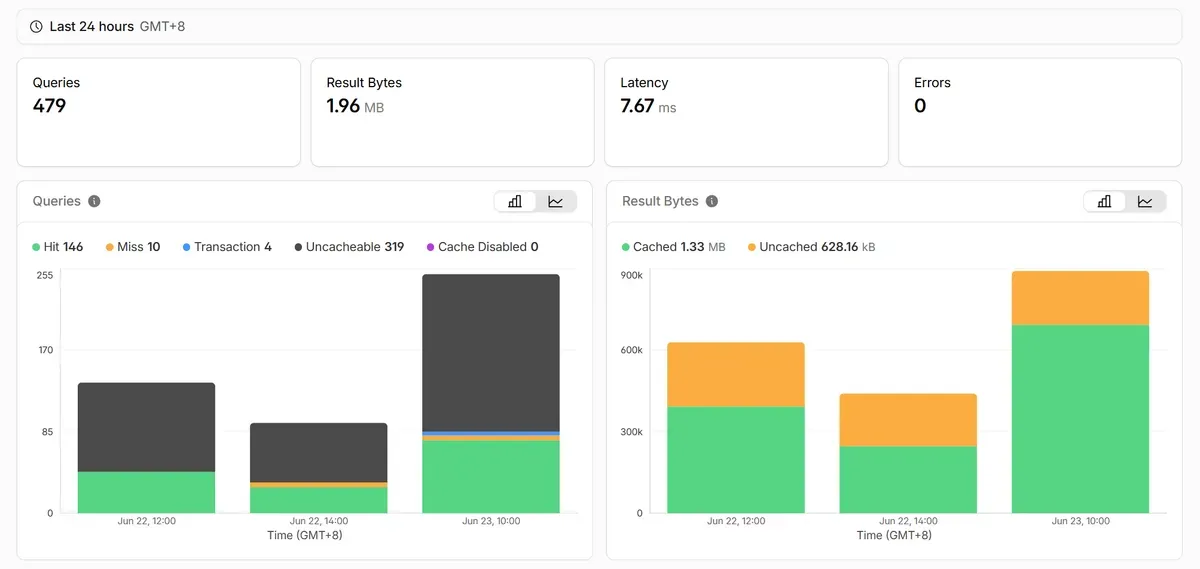
结语
这个事件让我意识到一个很严重的事情:
在不知不觉中,我已经养成了过度依赖AI的习惯,自己几乎停止了学习和思考,总是希望这个黑盒能帮我解决所有问题。
这可不是一个好现象。思来想去,我的决定是:
不管 AI 多厉害,多强大,知识还是要掌握在自己脑袋里,才是最夯实的。永远要保证自己对问题的理解和解决方案的掌控,而不是完全依赖 AI 的输出。
前几天找来了一些界面设计、产品设计相关的资料,每天还是要安排固定的时间学习才行。